AI 모델 서빙 병목 현상 해결 및 처리량 증대
설명
https://today.godd.app/project/91098daa-f5fe-4bb5-970a-39f8b6454bc1

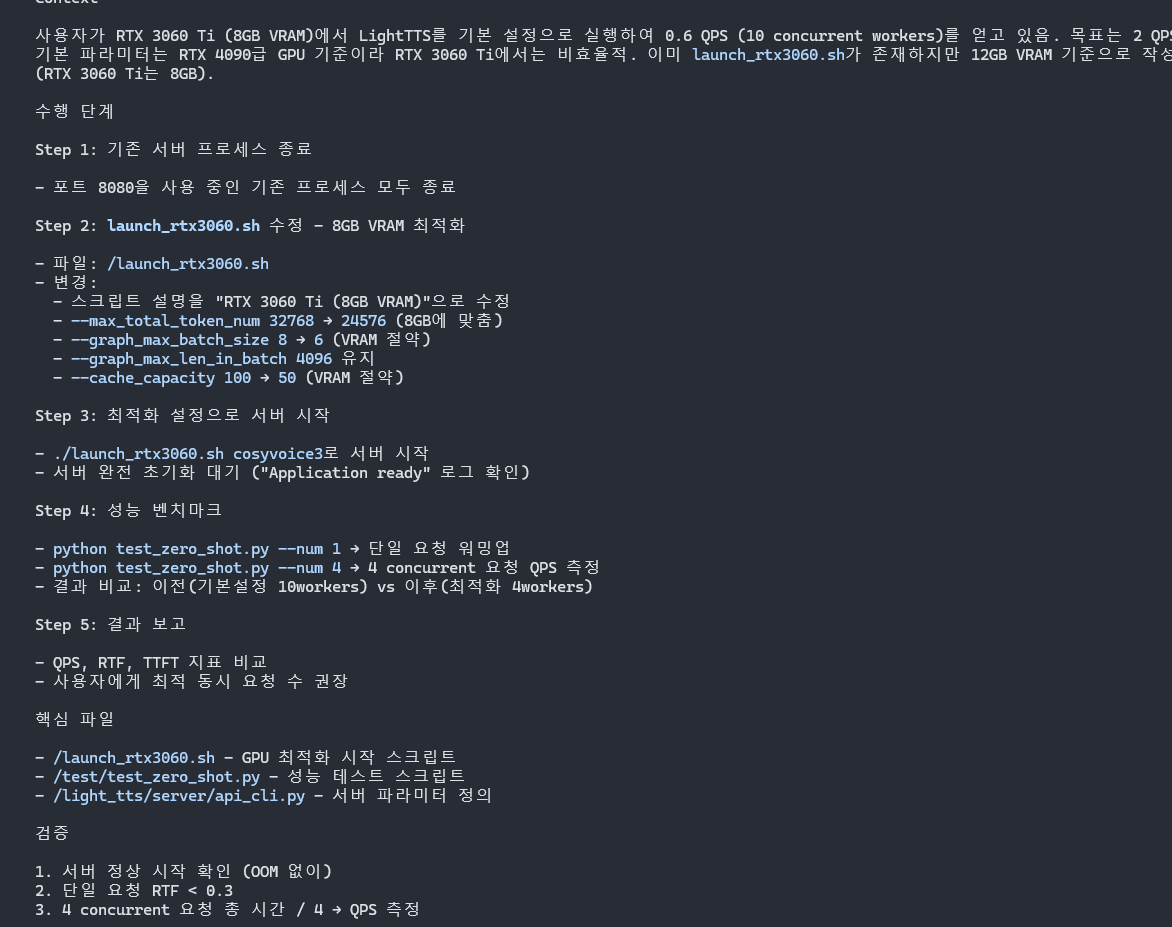
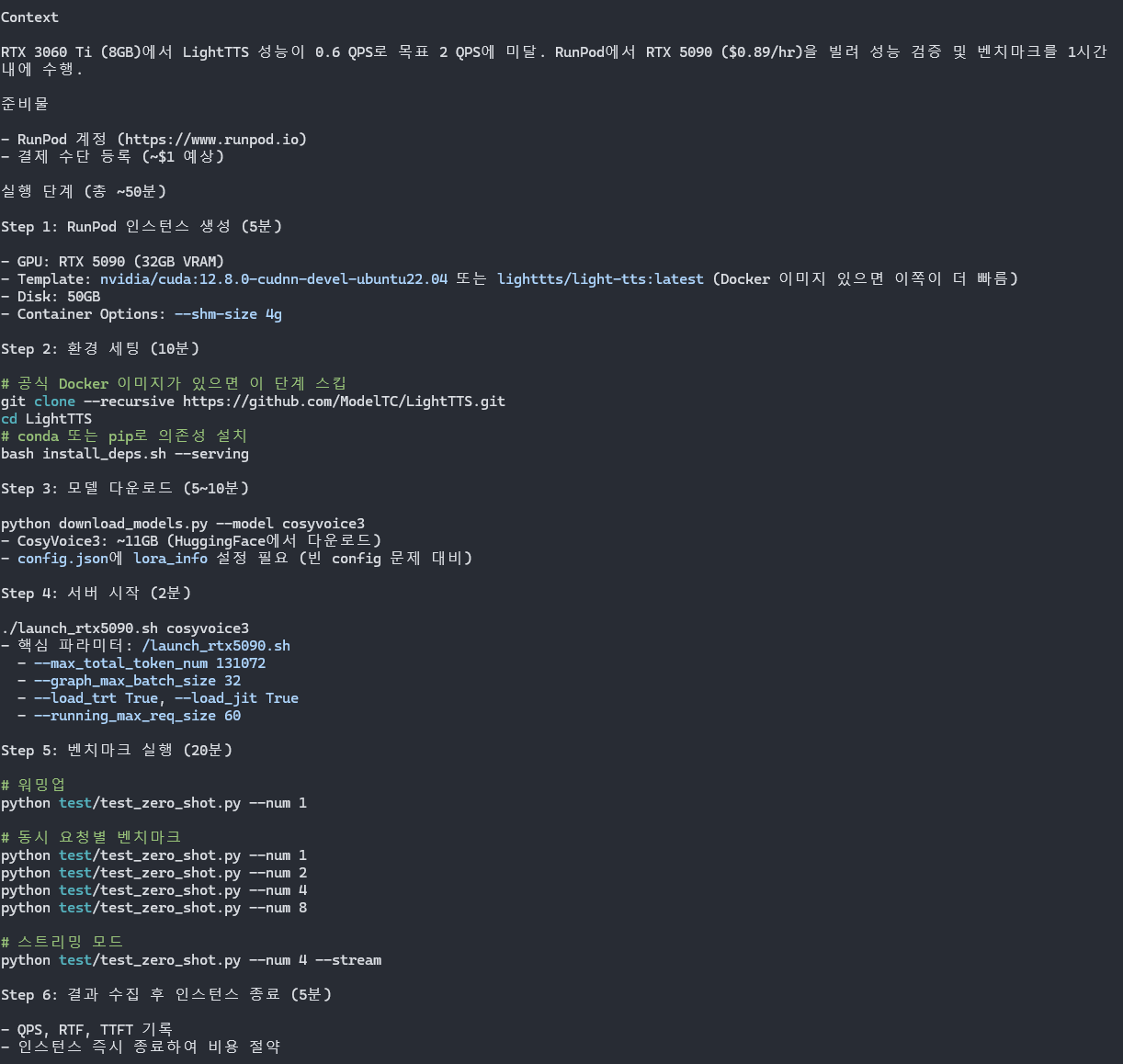
# 포트 죽이기
`kill $(lsof -t -i:8080) 2>/dev/null; pkill -f "light_tts.server.api_server" 2>/dev/null`
# runpod에서 실행
python -m light_tts.server.api_server \
--model_dir ./pretrained_models/Fun-CosyVoice3-0.5B-2512 \
--host 0.0.0.0 \
--port 8080 \
--max_total_token_num 131072 \
--graph_max_batch_size 32 \
--load_trt True \
--load_jit True \
--running_max_req_size 60 \
--data_type float16 \
2>&1 &
echo "Server PID: $!"
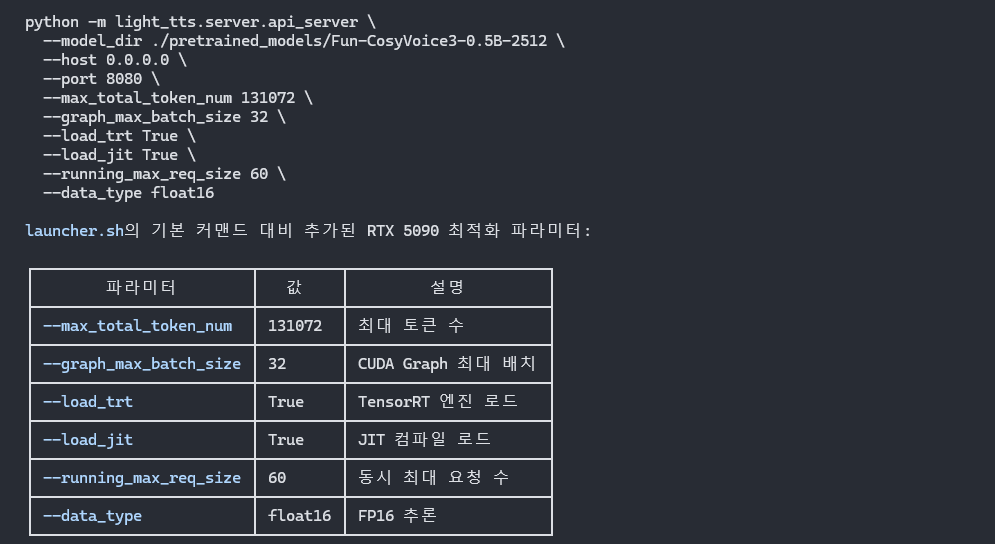
# 최적화
nvidia-cuda-mps-control -d
# 파일업로드
`curl -A "curl" -F 'file=@archive.tar.gz' https://0x0.st`